
前回の記事で「ControlNet」の1つの機能、”Pose to Image”を用いてモデルさんのポーズ情報から、AIイラストを生成するという方法について紹介しました。
今回はポーズだけでなく、「輪郭(Edge to Image)、深度(Depth to Image)」と言った情報を、AIイラストに反映させる方法について触れてみたいと思います。
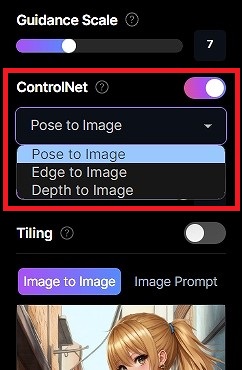
サイドバーにあるControlNetから、プルダウンメニューでそれぞれを選択することが出来ます。AIイラストの結果に大きく作用しますので、遊んでみると楽しいですよ。
フリー画像のモデルさんと同じポーズや同じ構図で作成できるので、生成できる画像の幅が広がります。

ControlNet
各モードの比較
以下のようなイメージをしていただけると、わかりやすいかと思います。

- Pose to Image
参考画像のポーズ(関節の角度、顔や体の向き、姿勢など)を入力値として使用する。
参考画像の性別、スタイルに関する特徴は含まれない。
と言った特徴があります。
ポーズ以外はAI任せという最も簡単なモードです。 - Edge to Image
参考画像のエッジ(輪郭)を入力値として使用する。
参考画像の性別、スタイル、絵の情報(アニメ、実写)、画像のサイズなどが、生成したいAIイラストが大きく異なっている場合、作画の崩れが発生しやすい。
という特徴があります。 - Depth to Image
参考画像の深度(オブジェクトの奥行きや距離)を入力値として使用する。
参考画像のモデルさんが手前に立っている場合、当然それも深度情報を持っています。したがって、参考画像の性別、スタイル、絵の情報(アニメ、実写)、画像のサイズと、生成したいAIイラストが大きく異なっている場合、作画の崩れが発生しやすい。
という特徴があります。
実際絵を見てもらったほうが、イメージしやすいと思います。
また、ControlNetの影響度の強さを示すControlNet Weightは1(最大)とします。
Pose to Image
まずは、Pose to Imageで画像生成しました。



参考画像(男性)と生成された画像(アニメ美少女)では印象がまるで異なります。しかし、参考画像の「ポーズ」だけは結果に反映されているのが確認できると思います。このように、Pose to Imageを使うとポーズだけを参考に、AIが画像生成してくれます。ポーズ以外の情報はPromptに基づきます。


参考画像が斬新な服装でも関係ありません。「ポーズ」だけを参考にしているため、性別、スタイル、服装などは一切反映されないのがこの「Pose to Image」です。
- 参考画像はポーズだけで選べば良い(性別やスタイルなどは考慮不要)
Edge to Image
続けてEdge to Imageです。参考画像の輪郭情報を用いるため、洋服のデザインや境界線の再現度が高くなります。
輪郭情報を用いるため、参考画像が実写で、生成したい画像がアニメという場合、上手くいかないことが多いです。以下は失敗例です。


これは、輪郭情報が実写とアニメで大きく異なるため発生するようです。
比較的うまくいった例はこちらになります。


輪郭(洋服の形や、アウターとインナーの境界線)という点においては、「Pose to Image」より再現度は高いものの、顔が不自然ですね。
この場合はPromptを修正し、生成されるAIイラストをモデルさんに近づけることで、上手くいく場合もあります。


少し自然になったでしょうか?参考までにいくつか例を載せておきます。





この様に参考画像の「輪郭(顔の形、目の大きさ、服装、スタイル)が強く引き継がれる結果」となっていることが確認できるかと思います。
- 参考画像の性別、スタイル、絵の情報(アニメ、実写)が生成されるAIイラストに影響する。
(実写には実写、アニメにはアニメの参考画像を用意したほうが良い) - 参考画像の大きさは、生成されるAIイラストと同じ大きさになるよう、トリミングした方が良い。
(参考画像と生成されるAIイラストの縮尺比が異なると、AIイラストの縮尺比にも影響します)

Depth to Image
最後が「Depth to Image」です。深度情報(距離感や奥行き感)をもとに、画像を生成しますので、3つのモードのうち、最も参考写真の位置関係を再現することが出来るモードとなります。
また、手前に立っているモデルさんにも当然、深度情報は存在しているため、Depth to Imageにおいても参考画像のモデルさんと、生成されるAIイラストとは近いほうが安定します。



Depth to Imageは奥行きのある画像を作成したいときに役立ちます。


背景の木々の様子や、道路の角度や位置など含め、かなり忠実に再現できているのではないでしょうか?この様に奥行き感のある画像を生成したいときに使えるモードです。
同じ参考画像で、Edge to Imageで生成するとどうなるでしょうか?

AIイラストの右上と左上には、本来手前には無いはずの何かが描かれていますね。Edge to Imageには深度情報がなく、輪郭をベースに生成するためこの様になってしまうのでしょう。
- 全体の構図を忠実に再現するというモードです。
- 参考画像の性別、スタイル、絵の情報(アニメ、実写)が生成されるAIイラストに影響する。
(Edge to Imageよりは若干緩いが、実写には実写、アニメにはアニメの参考画像を用意したほうが良い) - 参考画像の大きさは、生成されるAIイラストと同じ大きさになるよう、トリミングした方が良い。
(参考画像と生成されるAIイラストの縮尺比が異なると、AIイラストの縮尺比にも影響します)
上手くいかない時の調整方法
ControlNet Weightの調整
公式Discordの”tips-and-tricks“によれば、0.7 ~ 0.9が推奨とありますので、上手くいかない場合、ControlNet Weightの値を調整してみてください。
ControlNet Weight
The value of weight I recommend to keep in between of 0.7-0.9, as the value of 1 appears outline on the objects and text.
公式Discord
Edge to Image | Control Weight 0.75


weight 0.75まで落とすと、実写からアニメ絵を生成しても、weight 1.0より自然な画像が生成されることがわかりますね。という訳で、Edge to Imageがどうしても上手くいかないという方は、Control Weight の値を変更してみてください。
Depth to Image | Control Weight 0.7



Depth to Imageでも、weight 0.7まで落とすと自然が画像が生成されました。Depth to Imageが上手くいかないという方は、Control Weightの値を変更してみるとよいかと思います。
また、参考画像の表情が笑っている場合、Promptには smile, happy を入れるなど、参考画像に寄せてあげると安定するようでした。
まとめ
参考画像から精度の高いAIイラストを再現するControlNetの紹介でした。
ポーズ以外おまかせで良ければ、Pose to Imageを使うのが一番手っ取り早いです。また、どんな画像が生成されるか「ガチャガチャ」感覚で遊びたい方は、そもそもControlNetの機能を使用しなくても全然楽しめると思います。
というのも、ControlNetは上手く使えば画像生成の幅は広がるものの、思い通りにならずムキになってしまうと課金へまっしぐらです(^_^;)
次回は正式リリース(2023/5/16)となった Prompt Magic v2の紹介をしたいと思います。



コメント