

Remix機能で気軽に画像生成を楽しんだり、ControlNetで好きなポーズをとらせる方法を習得したら、次は「生成される被写体の顔って指定出来ないのかな?」に行き着くのではないでしょうか?
顔の造形をプロンプトで指示するなんて至難の業、こういう時はモデルトレーニング機能の出番です。自分のイメージや美的感覚をAIに学習させることで、AIはその学習データに基づき、あなた好みの画像を生成してくれるようになります。
Leonard.Aiであれば、使用できるモデル数に制限はあるものの、こちらの機能も無料で使用できます。
無料なら使わないと損なので、是非ともお試しください。ただし、無料ユーザーは失敗すると最大一ヶ月間再トレーニングできないので、注意事項についても紹介しておきます。
今回も、Leonard.AiのアプリのFAQ及び、公式Discordの”「tips-and-tricks」を参考にしています。なお、アプリのFAQと公式Discordの内容が相反する場合、更新日時の新しい公式Discordの情報を正としています

モデルトレーニングにあたって
無料ユーザーのトレーニングのチャンスは月に1度きり
無料でも使用できますが、以下のような制約事項があります。
無料ユーザー
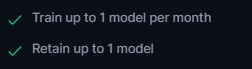
- トレーニングは1ヶ月に最大1回まで
- 保持できるモデルは最大1個まで
参考:課金ユーザー(Apprentice)
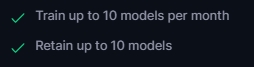
- トレーニングは1ヶ月に最大10回まで
- 保持できるモデルは最大10個まで
月に一度しかトレーニングが出来ない=無料ユーザーの方は失敗が許されません。
トレーニングさせる元画像の取り扱いを誤るとキレイに生成されませんので、以下の通り、正しく準備してから、モデルトレーニングを行うようにしてください。
モデルトレーニングの注意事項
40枚の高画質な画像を用意する
it is recommended that users take advantage of the maximum number of photos allowed in their training dataset. For instance, in this particular case, that limit is set at 40 photos.
In addition to this, it is crucial to use high-quality images during the training process.
公式Discordから抜粋
学習に使用する画像の数は多い方が良く、高画質であればあるほど良いとされています。
最大登録数は40枚なので、高画質な画像を40枚(可能な限り)用意しましょう。(ちなみに、最小値は5枚です。)
アスペクト比と統一する。
It is also important to ensure that the aspect ratio of all images is consistent.
公式Discordから抜粋
学習に使用する画像は、異なるアスペクト比のものは使わず、事前にアスペクト比を統一させるということです。
とても、大切なポイントだと思います。後の作業工程の中で、サイズ調整の方法を紹介します。
画像の一貫性を考慮する
If the dataset being used is for facial recognition, it is recommended to make it as close as possible or crop the images to only include the head rather than the full body or medium shot.
it is imperative to maintain consistency in the style of the images used for training.
公式Discordから抜粋
一例として、顔を学習させたい場合は、全身や腰より上の画像ではなく、被写体にできるだけ近寄り、頭部のみを切り取ったほうが良いと言われています。また、一貫性を持たせることが重要とあります。
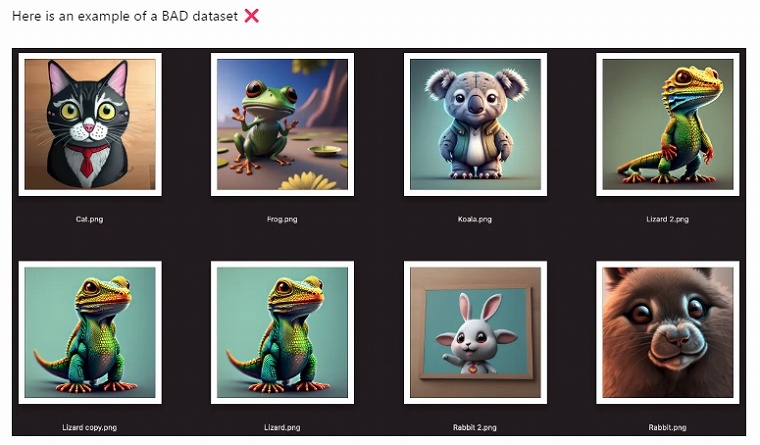
一貫性は、公式FAQの悪い例がわかりやすいです。例えば、上記の例では猫はマンガ調、カエルは余計な情報が多い?、コアラは3D、トカゲは似たのが多い。うさぎは額縁に入ってる。最後のうさぎはアップすぎる。
みたいな感じでしょうかね。したがって、アニメ絵と実写風を混ぜることは悪手で、consistency(一貫性)を守ることが大切だということですね。
さて、ここまでのまとめです。
- 40枚の高画質な画像を出来るだけ多く集める
- アスペクト比を調整する
- 画像の一貫性について考慮する
モデルトレーニングの方法
768×768の画像にトリミングする
Canvaというサービスを使えば、この様な画像のトリミングが出来ます。使っている方も多いかも知れませんが、AIイラストやるならとても便利なサイトです。無料で使えますので是非登録を。
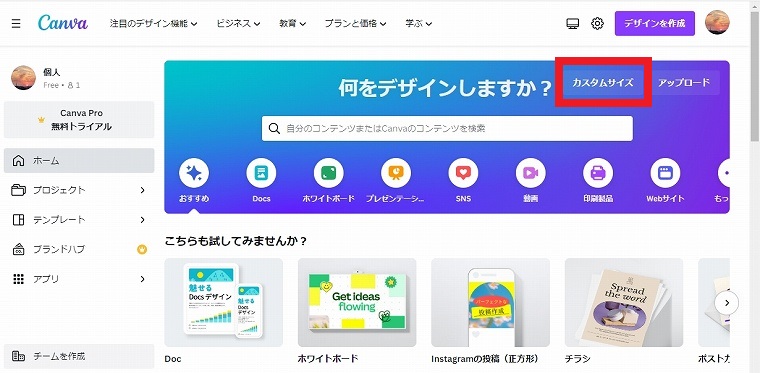
ログインするとこの様な画面になりますので、カスタムサイズをクリックします。
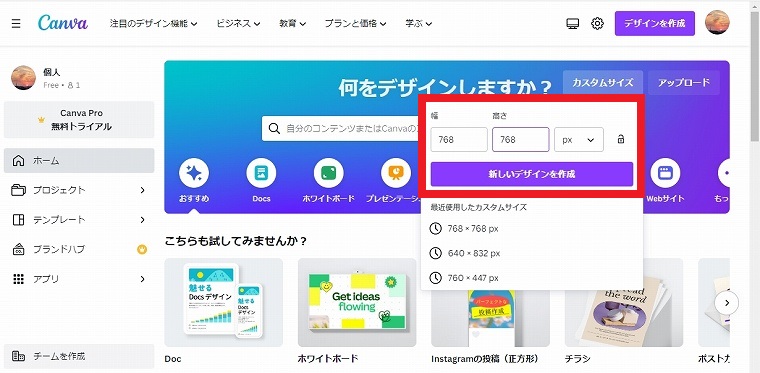
幅768、高さ768を入力し「新しいデザインを作成」をクリック
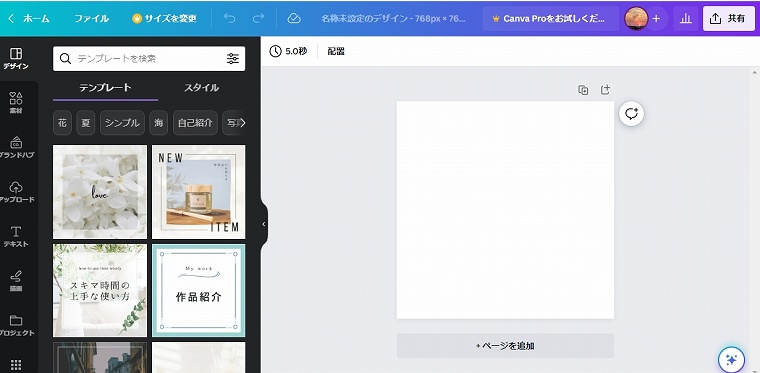
この様な画面になりますので、サイズを調整したい画像をドロップします。
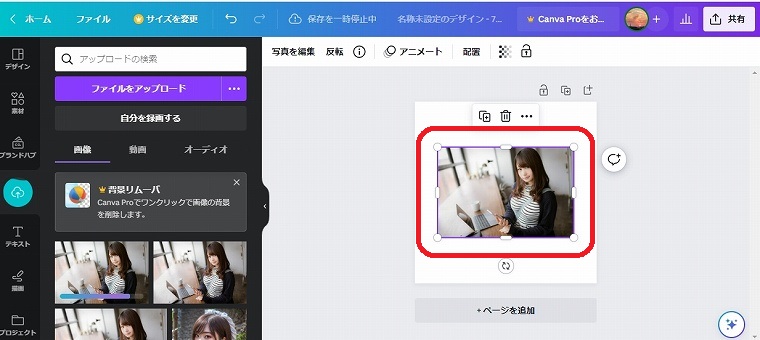
元画像を広げて、大きさを調整します。
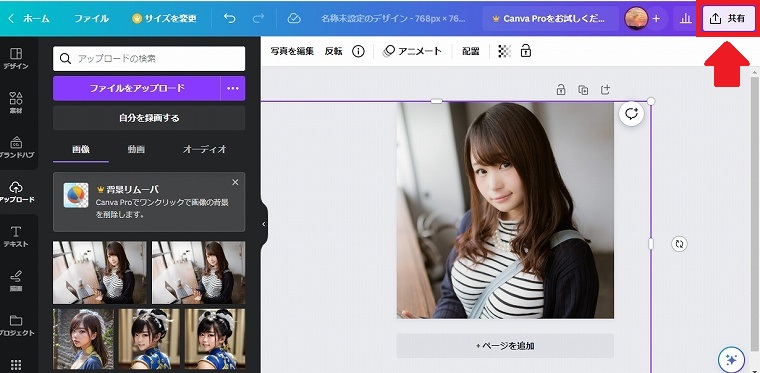
今回はこのくらいでカットする事にしました。構図が決まったら、右上の共有をクリックします。
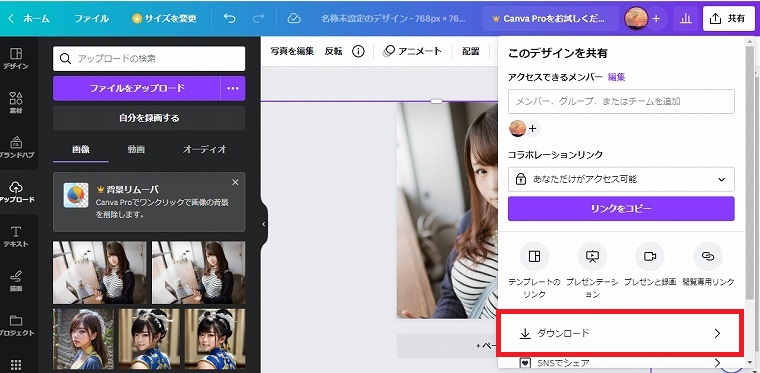
続けてダウンロードをクリックします。
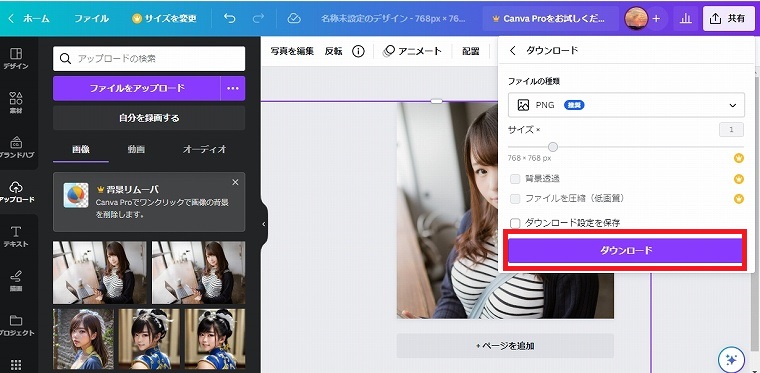
特にこだわりがなければ、PNG形式のままダウンロードをクリックします。
これを読み込ませる画像分繰り返してください。ここを怠ってしまうと、モデルトレーニングが上手くいかないので、面倒ですが頑張りましょう。
モデルトレーニング
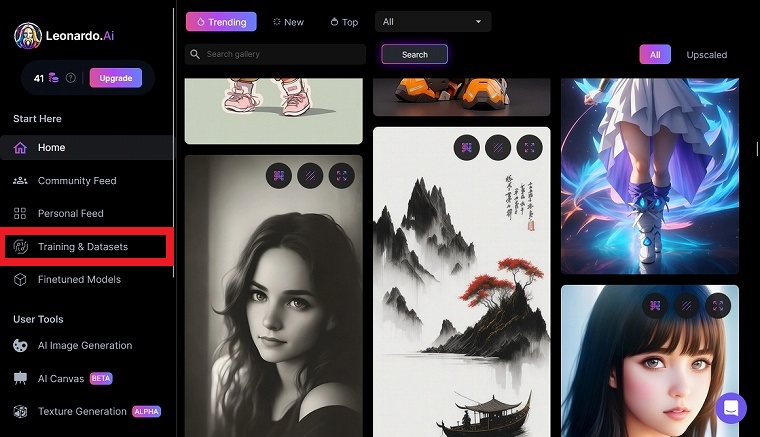
Leonard.Aiの画面から、「Training & Datasets」をクリックします。
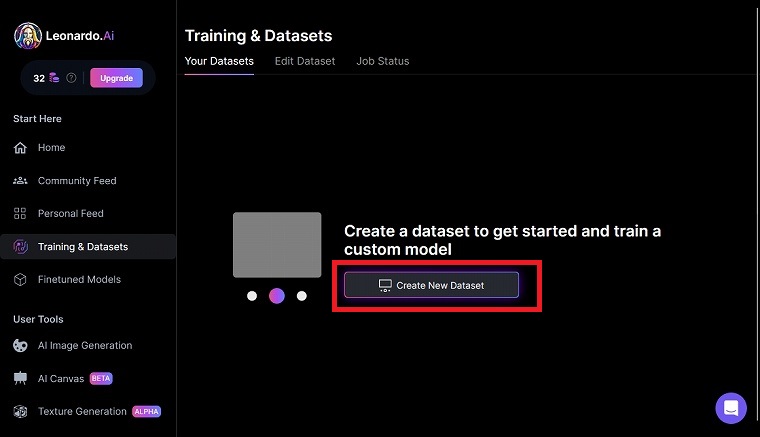
「Create New Dataset」をクリックします。
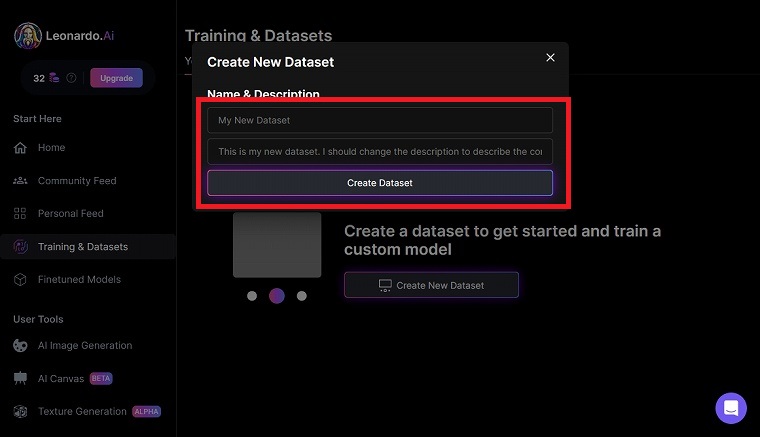
カスタムモデルの「名前」と「説明」を入力します。
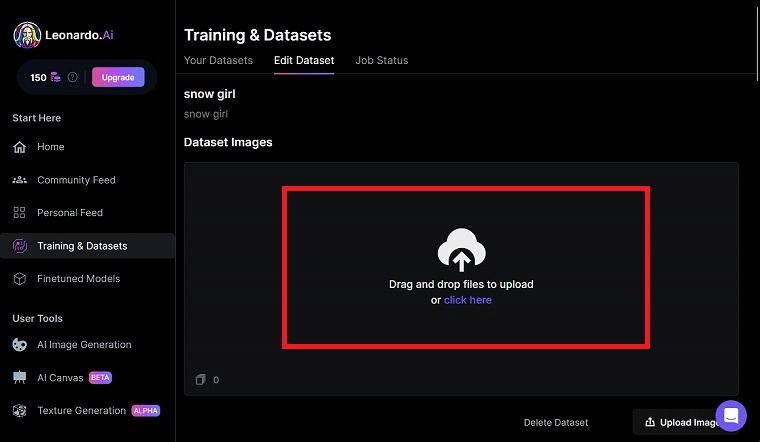
すると、この様な画面になりますので、学習させたい画像をドラッグ・アンド・ドロップしてください。
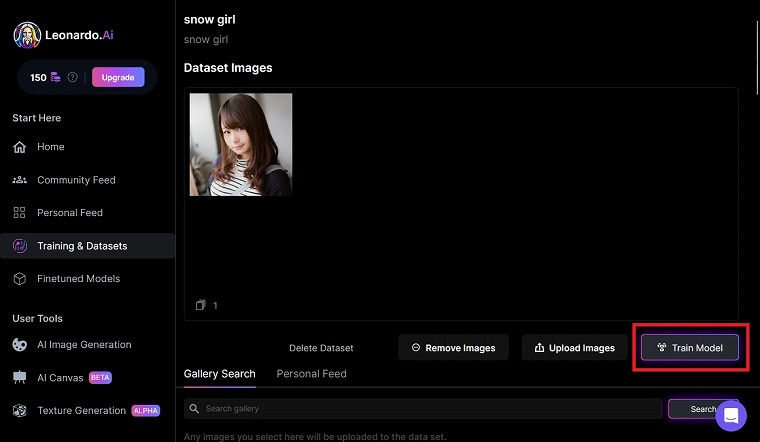
画像を読み込ませたら、「Train Model」をクリックして下さい。
(ここは手順の説明なので、1枚しかアップロードしてません。実際の手順では40枚アップロードして下さい。)
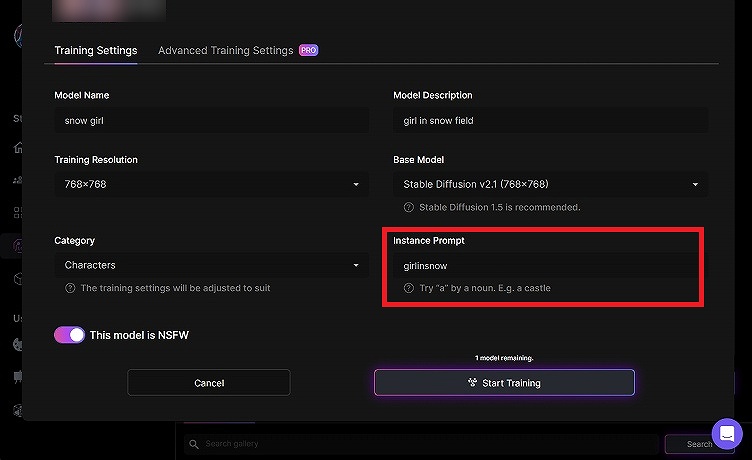
「Train Model」をクリックすると、この様な画面になるので必要な情報を入力します。
- Model Name
モデルの名前です。 - Model Description
モデルの説明です。 - Training Resolution
768×768を選択します。*1 後述 - Base Model
Stable Diffusion v2.1を選択します。 - Category
カテゴリーを選択します。 - Instance Prompt
ここだけちょっと意味のある設定です。プロンプトから呼び出す変数のような働きをします。
よく使うプロンプトと同じ名前(a pretty girlなど)にすると、ややこしいので分かりやすい名前にします。ここでは、”girlinsnow“としました。

*1 「SD1.5は一般的な条件下で良好、SD2.1はrealistic(実写と解釈)には良い」とあります。今回は実写なので、SD2.1を選択しました。(もうちょっと、説明文分かりやすく書いてほしい・・)
必要な項目の入力が終わったら、「Start Training」をクリックして下さい。
「モデルの学習には30~2時間程度必要です。完了したらメールします。」というメッセージが表示されるので、しばしお待ち下さい。
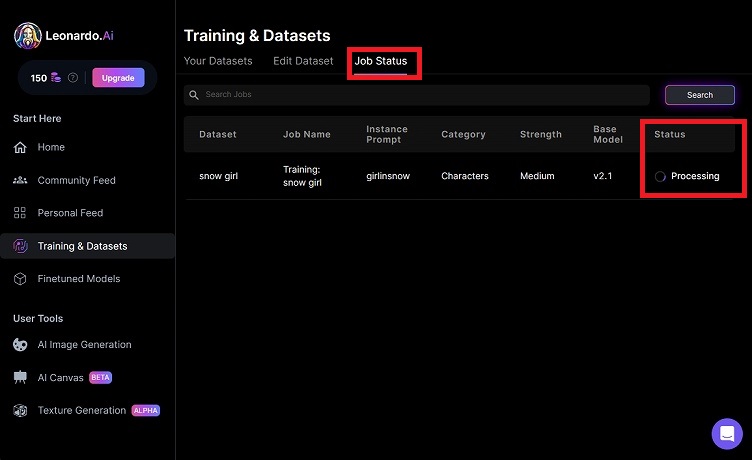
メール以外にも「Job Status」を確認して、Statusが「Proccesing」から「Done」に変わったら準備OKです。
カスタムモデルでの作成
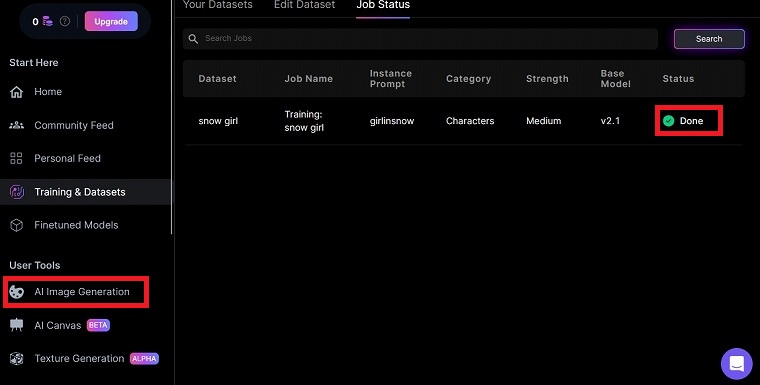
Statusが「Done」に変わったら準備OKです。後はいつも通り、「AI Image Genaration」からカスタムモデルを使ったAIイラストを生成していきましょう。
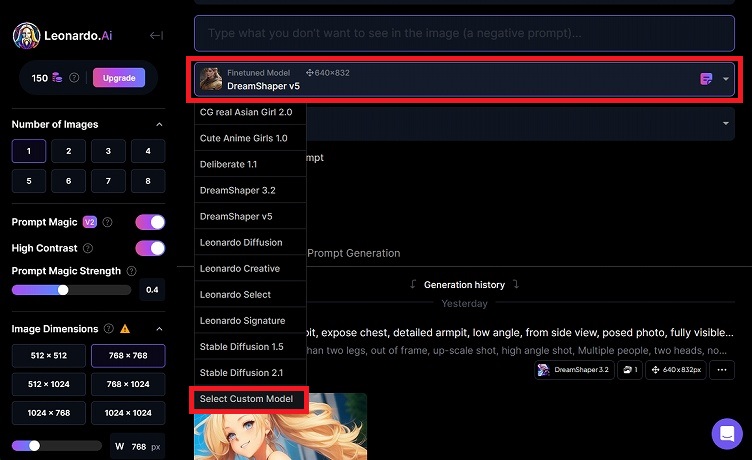
まずはカスタムモデルを選択するため、「Select Custom Model」をクリックします。
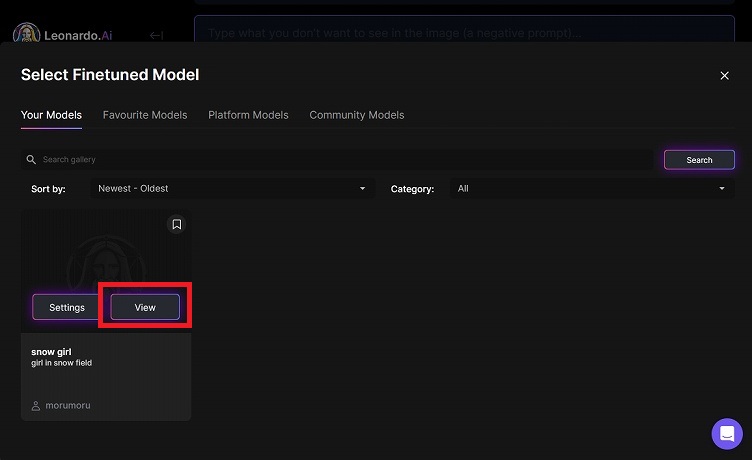
すると、「Your Models」に自分が作ったモデルがあると思いますので、Viewをクリックします。
「Generate with this Model」をクリックします。
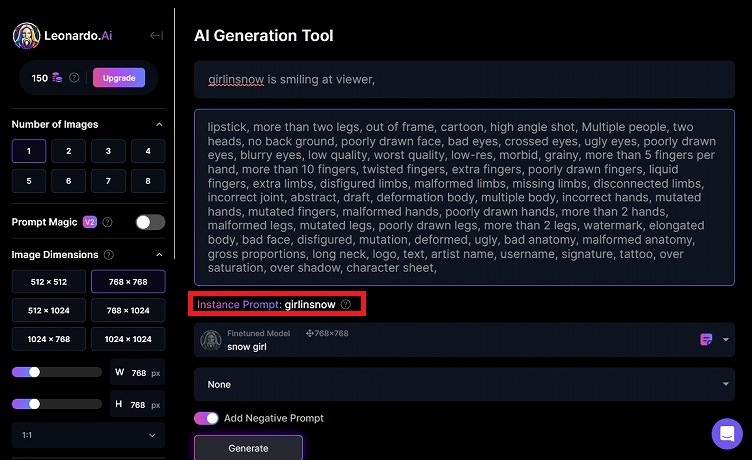
「Instance Prompt」に先程設定したインスタンスプロンプト名が表示されています。今回の例では「girlinsnow」と設定したので、その様に表示されております。
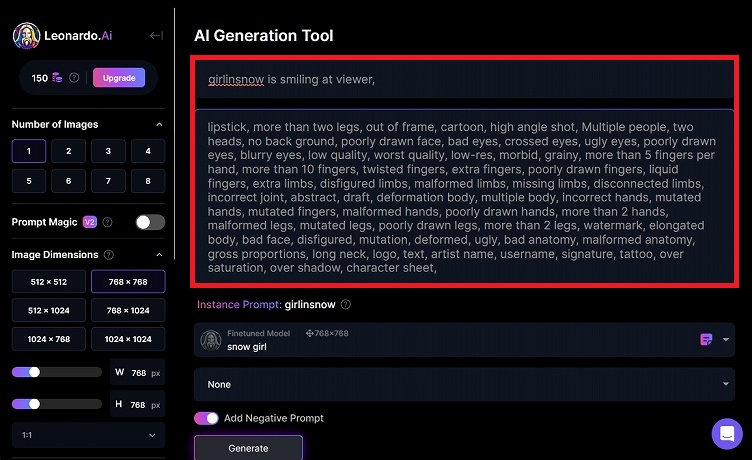
Promptに、Instance Prompt + アルファを入力します。ここで容姿に関するPromptは入れないほうが良いと思います。AIが変に解釈して、カスタムモデルと大きく異なる画像が生成されることがあります。
Negative Promptは、いつもどおりの呪文を入れていても特に問題はありませんでした。
準備できたら、Generateボタンをクリックして下さい。
生成された画像を確認
一回目から素晴らしい画像が生成されることもありますが、微妙な画像だった場合、以下の手法で錬成を試みて下さい。

2回目、3回目の錬成になると、結構いい絵が出力されます。

この様に自分が設定した画像に基づく、AI画像が生成されました。

いわゆる「世の中のAI顔」というのは、同じ様な要領で作られているんじゃないかと思います。
まとめ
イメージ通りの画像を生成させる「モデルトレーニング」についての紹介でした。
上手く生成できるかは、最初に用意できる画像数と画質に依存します。しかし、1日に150チケットも貰えるので、以下の錬成術を併用すれば1日に2,3枚は傑作が出来上がると思います。(Upscaleを使うのも手らしいですが、5トークンも消費する割にあまり上手くいかないんですよね。。)
そして、その出来上がった傑作だけを集めて、改めてモデルトレーニングをしてあげれば、絵の学習データはどんどん向上します。
ただ、こうなると無課金では厳しいです。月に1回しか学習させられないという事もありますが、カスタムモデルは1パターンしか保持できませんからね。こうなると必然的に1パターンの絵しか作れません。
「う~ん。じゃあ10ドルくらい、良いか?」といった感じで、無課金でも何とかなりますが、「使いこなせるようになってくると課金したくなる」という素晴らしいシステムです(笑)


コメント